paild 社でお手伝いをしている yuki です。前回に引き続き Dependency Injection 略して DI の話題を書いていきたいと思います。今回は Rust における DI についていろいろと考えてみました。今回紹介する実装はかなり単純な例を用いたもので、この記事からさらにみなさんのアプリケーションの実装状況に合わせていくつか工夫は必要になるかもしれません。ただ、とっかかりとしては十分なものになっていると思うので、DI でお困りの方はぜひ参考にしてみてください。
今回実装したいアプリケーションのお題について
今回サンプルを実装するコードの構成を簡単にまとめておきます。
まず、このアプリケーションは4層によって成り立っているものとします。4層なのは DI のサンプルとしては何層か用意されていた方がわかりやすいからという理由です。レイヤーがより少ないアプリケーションでももちろん応用可能です。実装自体はほぼダミー実装で、レイヤーに分けるのはやりすぎに見えますがそれはこうした事情からです。
今回は Router、Service、Repository、Database という層を作っています。細かくは解説しませんが、Router → Service → Repository → Database の順にリクエストが処理されていき、Database → Repository → Service → Router の順に各レイヤーのレスポンス(結果)が返却されていくものとします。
加えて、作ったコンポーネントたちを管理する構造体がいるものとします。AppModule というような名前にだいたいはなっているかと思います。これは、DI コンテナを用いた例では DI コンテナにあたり、そうでない例では「アセンブラ」[*1]と呼ばれるものにあたります。AppModule は actix-web の管理する共通データレイヤーに保持され、各レイヤーの取り出しは AppModule を経由して行われるものとします。また今回は、Service → Repository → Database の呼び出し規約を守らせるために、AppModule から取り出すのは Service レイヤーのもののみとします(直接 Repository を呼び出すというような、レイヤーの飛び越しを許容しないということです)。
図にすると下記のような依存関係になっているものとします。
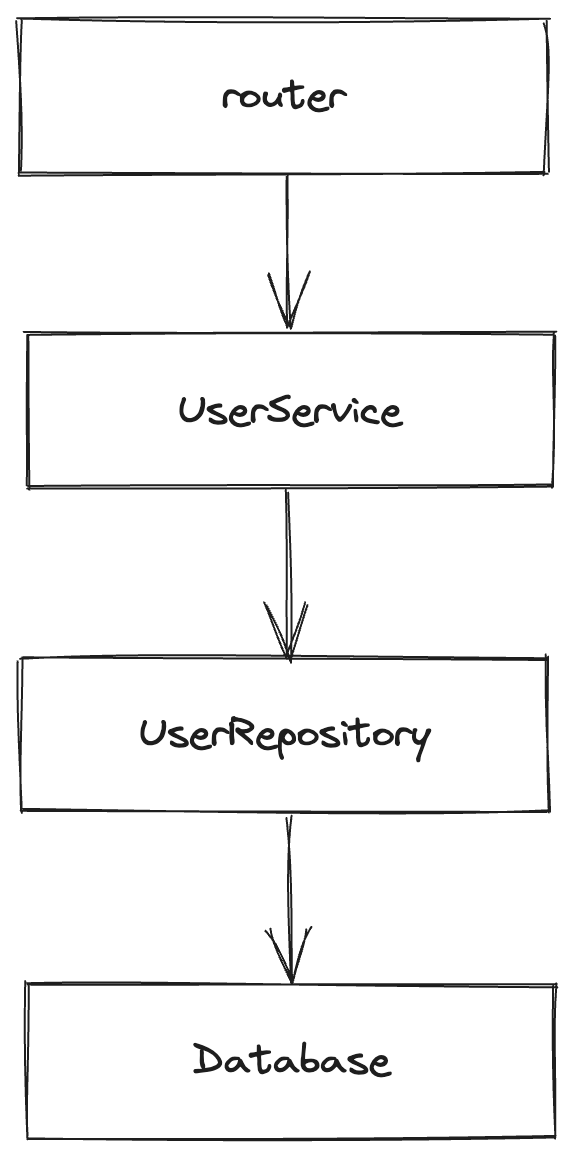
ちなみにですが、片手落ちかもしれませんが記事(と私の可処分時間)の都合上、テストコードについてはカットしています。あらかじめご了承ください。
今回紹介する技法の種別について
今回は下記の DI の方法について紹介します。
- コンストラクタインジェクション。
- shaku という DI コンテナクレートを使ったインジェクション。
- Cake Pattern (ケーキパターン、ないしはケイクパターン) を使ったインジェクション。
- Reader モナドを用いたインジェクション
なお、今回は記事の文字数の都合上、いくつかコードに関する記載を省く可能性があります。下記にサンプルコードがすべてコミットされていますので、深掘りしたい方は適宜そちらもあわせてご覧いただけますと幸いです。
また、前提として HTTP をしゃべるアプリケーションを実装するものとします。フレームワークとして actix-web を採用し、非同期処理を行い、並行処理安全性周りに気を遣う必要があるものとします。とくに非同期処理をするかしないかでは型付けの仕方が変わってくるので注意が必要です。
コンストラクタインジェクション
まず最初に紹介したいのは、いわゆるコンストラクタインジェクションです。ただ、Rust の場合は言語機能としてコンストラクタはないので注意が必要です。「構造体に直接 DI する」もしくは「new 関数を作って DI する」手法のことを総称して「コンストラクタインジェクション」とこの記事では便宜的に呼ぶことにします。
Rust でコンストラクタインジェクションをする場合、さらに2つのパターンが考えられます。Rust には静的ディスパッチと動的ディスパッチがあります。これらは構造体のフィールドにどのように値をもたせるかを分けさせることになるわけですが、DI においてもどちらを採用するかによって実装の仕方が少し変化します。
コンストラクタインジェクションは非常に素朴でシンプルな手法であるため、実際に私が現場で関わっているアプリケーションでもよく見ます。Servo のようなオープンソースの大きめのプロジェクトでも見かけます。paildのプロダクトのコードも、このサンプルのままではありませんが動的ディスパッチを用いたコンストラクタインジェクションを使用しています。
静的ディスパッチを用いたもの
まずは静的ディスパッチを用いるパターンを見ていきましょう。
具体的には下記のような構成になります。実装が長くなるため、具象実装側はコンストラクタを除き省いています。
use anyhow::Result; use common::User; pub struct UserService<UR: UserRepository> { repository: UR, } impl<UR: UserRepository> UserService<UR> { pub fn new(repository: UR) -> UserService<UR> { UserService { repository } } // 続く } pub trait UserRepository: Send + Sync + 'static { fn find_user(&self, id: String) -> Result<Option<User>>; fn update(&self, user: User) -> Result<()>; } pub struct UserRepositoryImpl { database: Database, } impl UserRepositoryImpl { pub fn new(database: Database) -> UserRepositoryImpl { UserRepositoryImpl { database } } } impl UserRepository for UserRepositoryImpl { // 続く } pub struct Database; impl Database { // 続く } pub struct AppModule { static_user_service: UserService<UserRepositoryImpl>, } impl AppModule { pub fn new() -> AppModule { let database = Database; let static_user_service = UserService::new(UserRepositoryImpl::new(database)); AppModule { static_user_service, } } pub fn static_user_service(&self) -> &UserService<UserRepositoryImpl> { &self.static_user_service } }
静的ディスパッチに特徴的なのは、なんといってもジェネリクスの使用でしょうか。たとえば UserService は「UserRepository トレイトが実装された型を渡してほしい」という制約を持ちうるわけですが、その際ジェネリクスとトレイト境界による型情報の明示が必要になります。たとえば次のようにです。
pub struct UserService<UR: UserRepository> { repository: UR, }
もちろんこれは、UserRepository を DIP するためにトレイトとしているためです。トレイトをわざわざ切ることなく渡す場合には、余計な型引数は不要になります。UserRepository の具象実装と Database の関係性がこれにあたります。基本的に Rust ではモックする可能性がある構造体はトレイトを切ることで抽象実装と具象実装を切り離しておき、そのトレイトを経由してモックオブジェクトを差し込むことが多いです。UserRepository はモックを挿し込む可能性が高いためこのようにしています。
pub struct UserRepositoryImpl { database: Database, }
必要なコンポーネントは必ず AppModule を経由して呼び出すようにしています。actix-web を利用している場合は、いわゆる State を利用してアプリケーション全体に対して AppModule を登録しておくと、ルーター側で抽出して利用できるようになるのでそれを利用するとよいと思います。下記のように呼び出す事ができます。
pub mod router { use actix_web::{get, web::Data, web::Path, HttpResponse}; #[get("/users/{id}")] pub async fn find_user(id: Path<String>, app_module: Data<crate::AppModule>) -> HttpResponse { let user = app_module.user_service.find_user(id.into_inner()); match user { Ok(Some(user)) => HttpResponse::Ok().json(user), Ok(None) => HttpResponse::NotFound().finish(), Err(_) => HttpResponse::InternalServerError().finish(), } } }
動的ディスパッチを用いたもの
続いて動的ディスパッチを用いるパターンです。
静的ディスパッチを用いるものとは異なり、トレイト側をインジェクションしたい場合にジェネリクスは使用しません。代わりにトレイトオブジェクト(dyn Trait)を使用します。具体的には次のような実装になります。
use std::sync::Arc; use anyhow::Result; use common::User; pub struct UserService { repository: Arc<dyn UserRepository>, } impl UserService { pub fn new(repository: Arc<dyn UserRepository>) -> UserService { UserService { repository } } // 実装 } pub trait UserRepository: Send + Sync + 'static { fn find_user(&self, id: String) -> Result<Option<User>>; fn update(&self, user: User) -> Result<()>; } pub struct UserRepositoryImpl { database: Database, } impl UserRepositoryImpl { pub fn new(database: Database) -> UserRepositoryImpl { UserRepositoryImpl { database } } } impl UserRepository for UserRepositoryImpl { // 実装 } pub struct Database; impl Database { // 実装 } pub struct AppModule { user_service: UserService, } impl AppModule { pub fn new() -> AppModule { let database = Database; let user_service = UserService::new(Arc::new(UserRepositoryImpl::new(database))); AppModule { user_service } } pub fn user_service(&self) -> &UserService { &self.user_service } }
静的ディスパッチのバージョンと比較すると、UserService のジェネリクスが不要になっていることがわかります。代わりに Arc<dyn UserRepository> をフィールドにもっていることもまた違いのひとつになっています。
pub struct UserService { repository: Arc<dyn UserRepository>, }
最後に各コンポーネントの呼び出しについてですが、静的ディスパッチ時と同様に AppModule を経由して呼び出すことに変わりはありません。actix-web で利用する際もやはり同様に State を経由して呼び出すことになるはずです。下記のように実装しましたが、コードは静的ディスパッチ時と変わりありません。
// 再掲になってしまうが、呼び出し側のコード自体は静的ディスパッチ時からまったく変更していない。 pub mod router { use actix_web::{get, web::Data, web::Path, HttpResponse}; #[get("/users/{id}")] pub async fn find_user(id: Path<String>, app_module: Data<crate::AppModule>) -> HttpResponse { let user = app_module.user_service.find_user(id.into_inner()); match user { Ok(Some(user)) => HttpResponse::Ok().json(user), Ok(None) => HttpResponse::NotFound().finish(), Err(_) => HttpResponse::InternalServerError().finish(), } } }
静的ディスパッチと動的ディスパッチの利点・欠点
静的ディスパッチについては下記のようにまとめられるでしょう。
- 利点
- 速度が速い。
- 欠点
- いわゆる単相化により具象実装分のコードが個別に生成されることになるので、一般にはバイナリサイズの肥大化に繋がる。
- 型引数を構造体に毎回書く必要が出てくるため、構造体に注入するオブジェクトの数が増えれば増えるほど、型引数の管理をする必要が出てくる。
動的ディスパッチについては下記のようにまとめられるでしょう。
- 利点
- 実行時に紐付けが解決されるので、静的ディスパッチのケースとは異なりバイナリサイズが具象実装分だけ肥大化することはない。
- コンパイル時にサイズが決定できないオブジェクトも管理できる。
- 静的ディスパッチのケースと比較すると型引数が不要になるので、とくに実装変更時の手間が少ない。
- 欠点
大きな意味があるかはわかりませんが、簡単にベンチマークをとってみました。今回のかなり単純なサンプルに限って言えば、ほとんど両者共に速度差なく呼び出しできるようです。ただしこれはかなり単純な例であり、プロダクションのコードレベルの複雑性を持った場合にどのような挙動になるかは未知数です。ベンチマーク計測用のコードはこちらに置いてあります。
static_dispatch time: [52.555 ns 52.736 ns 52.944 ns]
change: [+0.5560% +0.9297% +1.3027%] (p = 0.00 < 0.05)
Change within noise threshold.
Found 13 outliers among 100 measurements (13.00%)
8 (8.00%) high mild
5 (5.00%) high severe
dynamic_dispatch time: [52.791 ns 52.910 ns 53.105 ns]
Found 6 outliers among 100 measurements (6.00%)
2 (2.00%) high mild
4 (4.00%) high severe
私の個人的な好みで言えば、動的ディスパッチを利用してしまうのが好きです。単純に各コンポーネントにつく型引数の多さをはじめとする追加のパラメータで悩みたくないためです。ただし極限まで速度を求めたいケースではもしかすると静的ディスパッチを利用した DI の方が適しているケースもあるかもしれません。ユースケースを丁寧に考えたり、場合によっては両方のコードを書いて計測したりしてどちらを導入するかを柔軟に決めています。また、一般的な簡単な Web アプリケーション以外のアプリケーションを実装する場合には、配布物を作る際の制約等でどちらかしか選択できないケースもありえるでしょう。
shaku (DI コンテナ)を用いたインジェクション
続いて紹介するのは DI コンテナを用いた手法です。Rust にはこれといってデファクトスタンダードとなりうるような DI コンテナのクレートはまだないように思います。私自身も何かないかと思い調べてみたところ、shaku というクレートがまずまず使えそうでしたので紹介させていただきます。なお、私自身も本番環境で利用したことがあるわけではないため、ご自身のニーズに合うかどうかや潜在的なバグの可能性は拭いきれない点にご注意ください。
shaku は自動で依存関係を整理してくれつつ、コンパイル時に正しく依存関係をセットアップできているかを検証してくれる DI コンテナです。shaku の基本的な使い方は実際のコードを見てしまった方が早いと思うので、先にサンプルコードを示しておきます。
use std::sync::Arc; use anyhow::Result; use common::User; use shaku::{module, Component, Interface}; pub trait Database: Interface { fn find_user(&self, id: String) -> Result<Option<User>>; fn update(&self, user: User) -> Result<()>; } #[derive(Component)] #[shaku(interface = Database)] pub struct DatabaseImpl; impl Database for DatabaseImpl { // 具体的な実装が続く } pub trait UserRepository: Interface { fn find_user(&self, id: String) -> Result<Option<User>>; fn update(&self, user: User) -> Result<()>; } #[derive(Component)] #[shaku(interface = UserRepository)] pub struct UserRepositoryImpl { #[shaku(inject)] database: Arc<dyn Database>, } impl UserRepository for UserRepositoryImpl { // 具体的な実装が続く } pub trait UserService: Interface { fn find_user(&self, id: String) -> Result<Option<User>>; fn deactivate_user(&self, id: String) -> Result<()>; } #[derive(Component)] #[shaku(interface = UserService)] pub struct UserServiceImpl { #[shaku(inject)] user_repository: Arc<dyn UserRepository>, } impl UserService for UserServiceImpl { // 具体的な実装が続く } module! { pub AppModule { components = [UserServiceImpl, UserRepositoryImpl, DatabaseImpl], providers = [] } }
Repository の実装を例に見てみましょう。shaku では、まずインターフェース側に Interface というトレイトを継承させておく必要があります。
pub trait UserRepository: Interface { fn find_user(&self, id: String) -> Result<Option<User>>; fn update(&self, user: User) -> Result<()>; }
次に具象実装用の構造体を用意します。このとき、#[derive(Component)] と #[shaku(interface = UserRepository)] が必要になります。これはのちに DI コンテナで自動でトレイトと構造体の紐付けを行ったり、依存関係の解決を行うために使用されます。
#[derive(Component)] #[shaku(interface = UserRepository)] pub struct UserRepositoryImpl { #[shaku(inject)] database: Arc<dyn Database>, }
また、DI されるコンポーネントは #[shaku(inject)] によって指定することができます。このコンポーネントは DI コンテナ側で自動で依存関係等が処理された状態で生成されます。なお、#[shaku(inject)] を指定するコンポーネントは、上述の #[derive(Component)] と #[shaku(interface = UserRepository)] の付与が必要になります。これが設定されていないコンポーネントはコンパイル時にエラーとして検出されます。
DI コンテナは下記のようにして定義することができます。module! マクロ内に DI コンテナとして使用する構造体を定義しておきます。その中に、具象実装をする構造体(XXXImpl)を components に指定しておくだけです。
module! { pub AppModule { components = [UserServiceImpl, UserRepositoryImpl, DatabaseImpl], providers = [] } }
さて、依存関係を解決したコンポーネントを actix-web で取り出してみましょう。shaku は actix-web に使えるクレートを用意しているのでそれを利用して実装します。下記のように実装することができます。
pub mod router { use crate::{AppModule, UserService}; use actix_web::{get, web::Path, HttpResponse}; use shaku_actix::Inject; #[get("/users/{id}")] pub async fn find_user( id: Path<String>, service: Inject<AppModule, dyn UserService>, ) -> HttpResponse { let user = service.find_user(id.into_inner()); match user { Ok(Some(user)) => HttpResponse::Ok().json(user), Ok(None) => HttpResponse::NotFound().finish(), Err(_) => HttpResponse::InternalServerError().finish(), } } }
肝となるのは service: Inject<AppModule, dyn UserService> です。ここに依存関係が解決済みの UserServiceImpl が流れ込んできて、あとはルーターの処理の内部で呼び出しするだけで利用可能になっています。
shaku の利点・欠点
私も本番投入をしたことはなく、少し触った範囲でのメリットデメリットの検証にはなります。使いながら次のようなことを考えました。
- 利点
- 意外と設定を簡単にできる。余計な設定ファイルなどは一切不要で Rust コードですべて記述して完結する。
- 煩雑な依存関係の解決周りは裏で一挙に行ってくれる。ソフトウェアが大規模化した際に便利。
- 欠点
- 構造体のみでの DI は対応していない模様。必ずトレイトを切る必要がある。
余談: DI コンテナの種類について
DI コンテナは2種類あり、実行時に依存関係を解決するタイプのものと、コンパイル時に依存関係を解決するタイプのものがあります。コンパイル時の方が基本的には開発の早い段階でミスに気づけるので優れていると個人的に思う一方で、コンパイル時に解決するということはそれだけマクロなどのコンパイル時のコード自動生成の機構を多用することになり、コンパイルが重くなるという欠点もあります。実行時タイプのものはコンパイル時間は伸ばしません。また、実行時解決となるのでコンパイル時のものと比較すると設定がより柔軟にできる傾向にあります。一方、実行するまでミスに気づかないというデメリットがあります。
私の JVM 系言語での経験からで恐縮ですが、たとえばで両タイプにおける代表的なライブラリを紹介しておきます。実行時に依存関係を解決するタイプの DI コンテナとしては Java や Scala 等で使用できる Google Guice があげられるでしょう。また、コンパイル時に依存関係を解決するタイプのものとしては、Scala のみの提供ですが Macwire があげられます。Guice はとくに過去の経験ですが、非常に規模の大きい金融機関で使用するようなシステムで使われていても、かなり綺麗にコンポーネントを整理できていました。一方で、そうしたシステムではそもそもビルドにとても時間がかかるにも関わらず、依存関係の設定ミスに気づけるのは実行時ということで大変でした。
- GitHub - google/guice: Guice (pronounced 'juice') is a lightweight dependency injection framework for Java 8 and above, brought to you by Google.
- GitHub - softwaremill/macwire: Lightweight and Nonintrusive Scala Dependency Injection Library
Cake Pattern
最後に Cake Pattern を用いた手法を紹介します。私は元々 Scala エンジニアなのですが、Scala の界隈ではこの DI パターンを一時期よく見ました。Scala は非常に表現力が豊かな言語で、その中でもトレイトを使って DI を実現する手法になります。それを Rust に輸入して利用してみた記事がいくつかあるのですが、私もこれらを参考に実装を改めて行ってみました。
Cake Pattern そのものは下記の記事が参考になるかもしれません。
ただ今回の実装では、私が前職でいわゆる「Minimal Cake Pattern」と呼ばれる手法を使っており、そちらに慣れているために可能な限り Minimal 版に寄せるように実装しています[*3]。
実装の概略
Cake Pattern は前提知識なしにコードを読んだとしても、それぞれのトレイトが何をするものなのかがわかりにくいかもしれません。先に概要を説明しておきます。
Cake Pattern では下記3つのトレイトが必要になります。
UsesXXX: トレイトの実装を定義するトレイト。XXX: トレイト境界を明示するためのトレイト。ProvidesXXX: 依存を提供するトレイト。
そのため、たとえばこれまでの DI のサンプルコードでは UserRepository というトレイトを用意していましたが、このトレイトに対してさらに追加で2つのトレイトの用意が必要になります。加えて、トレイトの実装を用意するための実装ブロックと、最終的に依存を提供する AppModule という構造体分の実装ブロックが必要になります。
実際の実装
上記の規則を踏まえて実装をしてみると下記のようになります。
pub trait UsesDatabase: Send + Sync + 'static { fn find_user(&self, id: String) -> Result<Option<User>>; fn update(&self, user: User) -> Result<()>; } pub trait Database: Send + Sync + 'static {} impl<T: Database> UsesDatabase for T { fn find_user(&self, id: String) -> Result<Option<User>> { Ok(Some(User { id: "id-a".to_string(), effective: true, })) } fn update(&self, user: User) -> Result<()> { Ok(println!("updated user: {:?}", user)) } } pub trait ProvidesDatabase: Send + Sync + 'static { type T: UsesDatabase; fn database(&self) -> &Self::T; } pub trait UsesUserRepository: Send + Sync + 'static { fn find_user(&self, id: String) -> Result<Option<User>>; fn update(&self, user: User) -> Result<()>; } pub trait UserRepository: ProvidesDatabase {} impl<T: UserRepository> UsesUserRepository for T { fn find_user(&self, id: String) -> Result<Option<User>> { self.database().find_user(id) } fn update(&self, user: User) -> Result<()> { self.database().update(user) } } pub trait ProvidesUserRepository: Send + Sync + 'static { type T: UsesUserRepository; fn user_repository(&self) -> &Self::T; } pub trait UsesUserService: Send + Sync + 'static { fn find_user(&self, id: String) -> Result<Option<User>>; fn deactivate_user(&self, id: String) -> Result<()>; } pub trait UserService: ProvidesUserRepository {} impl<T: UserService> UsesUserService for T { fn find_user(&self, id: String) -> Result<Option<User>> { self.user_repository().find_user(id) } fn deactivate_user(&self, id: String) -> Result<()> { let user = self.user_repository().find_user(id)?; if let Some(mut user) = user { user.effective = false; self.user_repository().update(user)?; }; Ok(()) } } pub trait ProvidesUserService: Send + Sync + 'static { type T: UsesUserService; fn user_service(&self) -> &Self::T; } pub struct AppModule; impl AppModule { pub fn new() -> Self { Self } } impl Database for AppModule {} impl UserRepository for AppModule {} impl UserService for AppModule {} impl ProvidesDatabase for AppModule { type T = Self; fn database(&self) -> &Self::T { self } } impl ProvidesUserRepository for AppModule { type T = Self; fn user_repository(&self) -> &Self::T { self } } impl ProvidesUserService for AppModule { type T = Self; fn user_service(&self) -> &Self::T { self } }
各コンポーネントの呼び出しは、actix-web の State 機能を利用する点においては同じになります。一方で AppModule を経由して呼び出すのは同様なのですが、その際 Cake Pattern では関数を使ってコンポーネントの依存を呼び出しするのでそのように修正します。
pub mod router { use actix_web::{get, web::Data, web::Path, HttpResponse}; use crate::{ProvidesUserService, UsesUserService}; #[get("/users/{id}")] pub async fn find_user(id: Path<String>, app_module: Data<crate::AppModule>) -> HttpResponse { let user = app_module.user_service().find_user(id.into_inner()); match user { Ok(Some(user)) => HttpResponse::Ok().json(user), Ok(None) => HttpResponse::NotFound().finish(), Err(_) => HttpResponse::InternalServerError().finish(), } } }
Cake Pattern の利点・欠点
- 利点
- DI コンテナを用いないため外部クレートのような複雑性を持ち込まずに済む上、依存関係を自動で解決してくれる。
- コンパイル時に依存関係のミスに気づける。
- 型引数を増やさずに静的ディスパッチをできる。
- 欠点
- とにかくボイラープレートが多い。慣れが必要。
- また、最終的な結果にたどり着くまでに必要な手順が他の手法と比べると多い。
- Rust の実装の場合、デメテル原則を簡単に無視できてしまう。
余談: マクロによる欠点の解消
コードを見た瞬間に「ウッ…」となった方もいらっしゃるかもしれませんが、私個人としてもボイラープレートの量が気になります。元々 Scala 前提で設計されたパターンを流用しているので、Rust にすると少々冗長な箇所があるなと感じます。とくに AppModule 周りです。
Rust ではマクロが利用できるので、こうしたボイラープレートはある程度マクロで潰せそうな気がしますね。試しに AppModule 周りはマクロで潰してみましょう。今回は宣言マクロで十分対応可能なので、これを使って実装してみました。
#[macro_export] macro_rules! build_container { ($trait:ident, $module:ident) => { impl $trait for $module {} }; } #[macro_export] macro_rules! provide { ($provider:ident, $accessor:tt, $module:ident) => { impl $provider for $module { type T = Self; fn $accessor(&self) -> &Self::T { self } } }; } build_container!(Database, AppModule); build_container!(UserRepository, AppModule); build_container!(UserService, AppModule); provide!(ProvidesDatabase, database, AppModule); provide!(ProvidesUserRepository, user_repository, AppModule); provide!(ProvidesUserService, user_service, AppModule);
あるいは手続きマクロを使用するとさらに実装の導出を自動化できるかもしれません。ProvidesUserRepository トレイト、実装の定義周りと、AppModule へのトレイトの実装(build_container)はすべてマクロで自動生成して対処できるはずです。derive を使って実装を自動導出すればもう少しきれいに行きそうな気がしています。
いくつか実装方法は考えられますが、このようにマクロを使用することで Cake Pattern の導入時に抵抗感のあるボイラープレートはかなりの数削減できると筆者は考えています。今回紹介した対応策とセットであれば、Cake Pattern は十分実用に耐えうるものになるのではないでしょうか。
余談: Reader モナドを用いたインジェクション
最後は実用性はないかもしれませんが可能性の話を記しておきます。関数型プログラミングの一部の領域では Reader モナドと呼ばれる概念を使って DI をすることがあります[*4]。Reader モナドについてはこの記事では詳しく解説しませんが、いわゆる高階関数にモナドの性質を与えたものと一旦理解しておいてください。なので、高階関数による DI の一種とみなしても問題はないでしょう。
Reader モナドの実装
まず前提として、Rust でモナドを完璧に実装するのは難しいです。Rust にはきちんと機能する高階多相を実現する機能がないためです。[*5]今回はRust でいわゆる Reader モナドもどきを実装して対応してみることにします。下記は Reader モナドの具体的な実装の一例です。
#[derive(Clone)] pub struct Reader<'a, E, A> { // もし並行処理安全性を求めないなら、Rc にする手もある。 // 他の実装との整合性の兼ね合いで Arc を利用している。 run: Arc<dyn Fn(E) -> A + 'a>, } impl<'a, E: 'a + Clone, A: 'a> Reader<'a, E, A> { pub fn pure<F>(f: F) -> Reader<'a, E, A> where F: Fn(E) -> A + 'a, { Reader { run: Arc::new(f) } } pub fn flat_map<B, F>(self, f: F) -> Reader<'a, E, B> where F: 'a + Fn(A) -> Reader<'a, E, B>, B: 'a, { Reader { run: Arc::new(move |env| (f((*self.run)(env.clone()))).run(env)), } } pub fn map<B, F>(self, f: F) -> Reader<'a, E, B> where F: 'a + Fn(A) -> B, B: 'a, { Reader { run: Arc::new(move |env| f((*self.run)(env))), } } pub fn local<F>(self, f: F) -> Reader<'a, E, A> where F: 'a + Fn(E) -> E, { // 用意はしたものの、今回は利用しないため解説を省きます。 } pub fn run(&self, env: E) -> A { (self.run)(env) } } pub fn ask<'a, E: 'a + Clone>() -> Reader<'a, E, E> { Reader::pure(|env| env) }
まず Scala などで実装する場合とは異なり、Rust ではライフタイムが絡んでくるためその分型パラメータの数が増えています。Scala ではたとえば Reader[E, A] と示せていたものを、Rust ではライフタイム識別子を追加して Reader<'a, E, A> と示す必要が出てきます。E はその関数を適用する際に利用する環境を表し、A はその関数を適用した結果得られる値の型です。
続いて処理中によく登場する関数について簡単に解説します。
Reader#pure: Reader 型を作るために必要になる関数です。コンストラクタに近い存在です。実はモナドの構成要素になります。Reader#flat_map: Rust のそれと同じ役割ですが、A->Reader<_, _, B>というような関数を受け取り、Reader<_, _, B>を返す高階関数です。実はモナドの構成要素になります。Reader 型同士を合成する際に使用します。Reader#map: Rust のそれと同じ役割ですが、A->Bというような関数を作り、Reader<_, _, B>を返す高階関数です。Reader#run: 関数適用をします。ask:Eの環境をもつ Reader を構築します。
実際の実装
これを先ほどの例に適用すると、たとえば下記のようにすることができるかなと考えています。サンプルコードはかなり単純であるため、何が楽になったのかわかりにくいかもしれません。ただ、とくに注目に値するのは UserService#deactivate_user の一連の処理でしょうか。「ユーザーを探す処理」「ユーザーをdeactivateし、更新する処理」を2つの関数に見立て、それぞれの関数を flat_map を用いて合成しています。内部では UserRepository を経由した関数をいくつか呼び出しています。
pub struct UserService; impl UserService { pub fn find_user<'a>(&self, id: String) -> Reader<'a, Arc<AppModule>, Result<Option<User>>> { ask().flat_map(move |module: Arc<AppModule>| module.user_repository.find_user(id.clone())) } pub fn deactivate_user<'a>(&self, id: String) -> Reader<'a, Arc<AppModule>, Result<()>> { ask() .flat_map(move |module: Arc<AppModule>| module.user_repository.find_user(id.clone())) .flat_map(|user| { if let Ok(Some(user)) = user { ask().flat_map(move |module: Arc<AppModule>| { let mut user = user.clone(); user.effective = false; module.user_repository.update(user) }) } else { Reader::pure(|_| Ok(())) } }) } } pub trait UserRepository: Send + Sync + 'static { fn find_user<'a>(&self, id: String) -> Reader<'a, Arc<AppModule>, Result<Option<User>>>; fn update<'a>(&self, user: User) -> Reader<'a, Arc<AppModule>, Result<()>>; } #[derive(Clone)] pub struct UserRepositoryImpl; impl UserRepository for UserRepositoryImpl { fn find_user<'a>(&self, id: String) -> Reader<'a, Arc<AppModule>, Result<Option<User>>> { ask().map(move |module: Arc<AppModule>| module.database.find_user(id.clone())) } fn update<'a>(&self, user: User) -> Reader<'a, Arc<AppModule>, Result<()>> { self.find_user(user.id).flat_map(|user| { if let Ok(Some(user)) = user { Reader::pure(move |module: Arc<AppModule>| module.database.update(user.clone())) } else { Reader::pure(|_| Ok(())) } }) } } #[derive(Clone)] pub struct Database; impl Database { // 他の実装パターンとまったく同じなので省略 } pub struct AppModule { pub user_repository: Arc<dyn UserRepository>, pub database: Database, } // ... 続く
あとは UserService をどこかしらから呼び出すわけですが、それは run 関数に AppModule を渡すことで実現できます。この部分が依存を注入している箇所にあたります。[*6]
pub mod router { use actix_web::{get, web::Data, web::Path, HttpResponse}; #[get("/users/{id}")] pub async fn find_user(id: Path<String>, app_module: Data<crate::AppModule>) -> HttpResponse { let user = app_module .user_service .find_user(id.into_inner()) .run(app_module.into_inner()); match user { Ok(Some(user)) => HttpResponse::Ok().json(user), Ok(None) => HttpResponse::NotFound().finish(), Err(_) => HttpResponse::InternalServerError().finish(), } } }
基本的な実装をだいたい行ったところで、最後にマクロを用いてもう少し便利にしておきましょう。flat_map にはコールバック地獄を引き起こしやすいという問題点があります。これを回避できるように、Scala では for-yield という専用の構文が導入されています。これを利用することにより、flat_map を用いた関数の合成を宣言的に記述できるようになります。
Rust でもマクロを用いればこうした宣言的な記法を可能にすることができるようになります。先ほどの deactivate_user を例にとって簡単に実装してみましょう。
まずは mdo というマクロを用意します。このマクロを使うことで、最終的に deactivate_user を下記のように記述できるようにすることを目指します。
pub fn deactivate_user<'a>(&self, id: String) -> Reader<'a, Arc<AppModule>, Result<()>> { // 元のコードは下記の通りでしたね。 // ask() // .flat_map(move |module: Arc<AppModule>| module.user_repository.find_user(id.clone())) // .flat_map(|user| { // if let Ok(Some(user)) = user { // ask().flat_map(move |module: Arc<AppModule>| { // let mut user = user.clone(); // user.effective = false; // module.user_repository.update(user) // }) // } else { // Reader::pure(|_| Ok(())) // } // }) mdo! { module <- ask::<Arc<AppModule>>(); user <- module.user_repository.find_user(id.clone()); ret if let Ok(Some(user)) = user { module.user_repository.update(user) } else { Reader::pure(|_| Ok(())) } } }
left <- right の行は、1行ごとに flat_map が走ります。右辺で計算した結果を左辺で一時的に保持しておき、その左辺の結果を次の1行に渡していくことになります。たとえば、module <- ask::<Arc<AppModule>>() は、ask 関数を呼び出して環境情報を手に入れた後、この環境情報を次の行に渡しています。次の行の module.user_repository.find_user(id.clone()) を実行する際には、裏でこの環境情報が渡された状態で処理が行われます。これを繰り返します。
式の結果の値を mdo 内の一連の処理の結果として返したい場合には、ret という構文を用いるものとします。この ret の後ろに記述された式が最終的な結果として返されるものとします。
このマクロを実現するためには下記のように定義すればよいでしょう。<- を用いた特殊な記法は要するに関数と次の処理へ渡したい値の定義場所が変わっただけですので、裏で flat_map の要求する順序に入れ替えてコードを生成してやれば十分ということになります。
#[macro_export] macro_rules! mdo { ($i:ident <- $e:expr; $($rest:tt)*) => { $e.flat_map(move |$i| mdo!($($rest)*)) }; // ... (ret $e:expr) => { $e }; }
これで Reader モナドを快適に利用するための準備は一通り揃ったはずです。
Reader モナドの利点・欠点
Reader モナドそれ自体の利点・欠点はさまざまな解説記事があるのでそちらに譲ることにします。
Rust での利用についてですが、実際に実装してみて個人的には苦しいのかなと思いました。Rust はクロージャーが噛むとボローチェッカーが急に牙を剥いてくる関係で、たとえば Scala のような言語ならばスッと書ける処理がまどろっこしくなります。[*7]また、Scala の for-yield のような機構を持ち合わせてはいないため、どうしてもコールバック地獄が起こりがちになります。マクロを利用すればそれに近い記法を実現はできますが、マクロはマクロでフォーマッタが効かなかったりデバッグが難しくなったりと辛いポイントが多いのも事実でしょう。
アイディアとしてはおもしろいと思うので、どなたか改善してくださる方がいればぜひお願いします。
まとめ
今回の記事では Rust を使ったさまざまな DI の手法について確認してみました。コンストラクタインジェクションは非常に一般的な方法でわかりやすいものだと思います。トレイトのみで実現できる DI として Cake Pattern を紹介しました。Rust の DI コンテナについても簡単に紹介をしました。
今後もう少し Rust のエコシステムが充実してくると、たとえば Spring 系のようにフレームワークの中に DI コンテナを持ち、一気通貫で管理できるようなクレートが登場してくるかもしれません。引き続きこの辺りの動向については定期的にチェックしておきたいなと思いました。
*1:アセンブラは Martin Fowler の原典に実は登場します。
*2:この記事の実験によれば、動的ディスパッチの使用によりたとえば関数のインライン化などは無効化されるケースがあることがわかります: Rust Dynamic Dispatching deep-dive | by Marco Amann | Digital Frontiers — Das Blog | Medium
*3:ちなみにですが、私はこちらの方が好きです。オリジナルのものは自分型アノテーションが入ってきてしまうのですが、あれが少々わかりにくかったためです。
*4:ならびに、Kleisli でしょうか
*5:GATs は?という話があるかもしれませんが、GATs では高階多相に求められる種々の規則を完全には守らせることはできません。https://zenn.dev/yyu/articles/f60ed5ba1dd9d5
*6:app_module から一度 user_service を呼び出して、その後もう一度 app_module を注入する、みたいな構図になってしまっており、なかなかにどうなんだろうと思ってはいます。実は UserService という構造体は他の DI 実装パターン用に残しているだけで不要だなと思っていて、find_user だけ関数として外部に切り出されていればよいのだと思います。そうすると、find_user 関数に対して外から run を経由して AppModule を渡す、という構図に直すことができます。
*7:変数に再度値を束縛し直してライフタイムを延命したり、clone が必要になったり、借用による持ち回しを考慮する必要が出てくるなどです。